KNN – Thuật toán láng giềng gần nhất K-Nearest Neighbor, trong việc nghiên cứu định lượng thì việc gặp phải KNN là mộ trong những lý thuyết làm cho nghiên cứu viên ” khó chịu” nhất, thông thường chúng ta gặp nhiều trong phương pháp định lượng điểm xu hướng PSM, hay mô hình máy học Malchine Learning – ML …oán
KNN – Thuật Toán Láng Giềng Gần Nhất
K-Nearest Neighbor là gì ?
Thuật toán k-láng giềng gần nhất, còn được gọi là KNN hoặc k-NN, là một bộ phân loại học có giám sát, phi tham số, sử dụng khoảng cách gần nhất để thực hiện phân loại hoặc dự đoán về việc nhóm một điểm dữ liệu riêng lẻ. Trong khi nó có thể được sử dụng cho các bài toán hồi quy (Regression) hoặc phân loại (Classification) , nó thường được sử dụng như một thuật toán phân loại, giải quyết giả định rằng các điểm tương tự có thể được tìm thấy gần nhau.
Đặc điểm của Thuật toán láng giềng gần nhất
- K-Nearest Neighbor là một trong những thuật toán Machine Learning đơn giản nhất dựa trên kỹ thuật Supervised Learning.
- Thuật toán K-NN giả định sự giống nhau giữa trường hợp / dữ liệu mới và các trường hợp có sẵn và đặt trường hợp mới vào danh mục giống nhất với các danh mục có sẵn.
- Thuật toán K-NN lưu trữ tất cả dữ liệu có sẵn và phân loại một điểm dữ liệu mới dựa trên sự tương đồng. Điều này có nghĩa là khi dữ liệu mới xuất hiện thì nó có thể dễ dàng được phân loại vào loại tốt bằng cách sử dụng thuật toán K-NN.
- Thuật toán K-NN có thể được sử dụng cho Hồi quy cũng như Phân loại nhưng chủ yếu nó được sử dụng cho các bài toán Phân loại.
- K-NN là một thuật toán phi tham số , có nghĩa là nó không đưa ra bất kỳ giả định nào về dữ liệu cơ bản.
- Nó còn được gọi là thuật toán lười học vì nó không học từ tập huấn luyện ngay lập tức thay vào đó nó lưu trữ tập dữ liệu và tại thời điểm phân loại, nó thực hiện một hành động trên tập dữ liệu.
- Thuật toán KNN ở giai đoạn huấn luyện chỉ lưu trữ tập dữ liệu và khi nó nhận được dữ liệu mới, sau đó nó sẽ phân loại dữ liệu đó thành một loại gần giống với dữ liệu mới.
Ví dụ: Giả sử, chúng ta có một hình ảnh của một sinh vật trông giống như mèo và chó, nhưng chúng ta muốn biết đó là mèo hay chó. Vì vậy, để nhận dạng này, chúng ta có thể sử dụng thuật toán KNN, vì nó hoạt động trên một thước đo độ tương đồng. Mô hình KNN của chúng tôi sẽ tìm các đặc điểm tương tự của tập dữ liệu mới đối với hình ảnh chó và mèo và dựa trên các đặc điểm tương tự nhất, mô hình này sẽ đưa nó vào danh mục mèo hoặc chó.

Tại sao chúng ta cần KNN
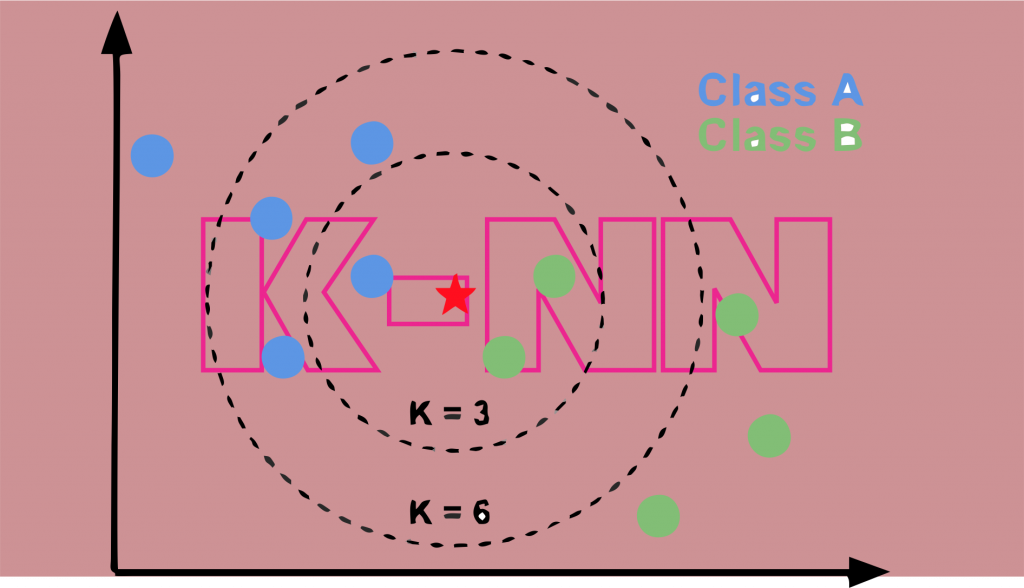
Giả sử có hai danh mục, tức là Danh mục A và Danh mục B, và chúng ta có một điểm dữ liệu mới x1, vậy điểm dữ liệu này sẽ nằm trong danh mục nào trong số các danh mục này. Để giải quyết dạng bài toán này, chúng ta cần một thuật toán K-NN. Với sự trợ giúp của K-NN, chúng ta có thể dễ dàng xác định danh mục hoặc lớp của một tập dữ liệu cụ thể. Hãy xem hình ảnh ở trên.
K-NN hoạt động như thế nào?
Hoạt động K-NN có thể được giải thích dựa trên thuật toán dưới đây:
- Bước 1: Chọn số K của những người hàng xóm
- Bước 2: Tính khoảng cách Euclide của K số láng giềng
- Bước 3: Lấy K láng giềng gần nhất theo khoảng cách Euclide được tính toán.
- Bước 4: Trong số k lân cận này, hãy đếm số điểm dữ liệu trong mỗi loại.
- Bước-5: Gán các điểm dữ liệu mới cho danh mục đó mà số lượng hàng xóm là tối đa.
- Bước 6: Mô hình của chúng tôi đã sẵn sàng.

Giả sử chúng ta có một điểm dữ liệu mới và chúng ta cần đặt nó vào danh mục bắt buộc. Chúng ta hãy xem hình ảnh ở trên:
- Đầu tiên, chúng ta sẽ chọn số lượng hàng xóm, vì vậy chúng ta sẽ chọn k = 5.
- Tiếp theo, chúng ta sẽ tính toán khoảng cách Euclid giữa các điểm dữ liệu. Khoảng cách Euclide là khoảng cách giữa hai điểm mà chúng ta đã học trong hình học. Công thức khoản cách được tính như trên.
- Bằng cách tính toán khoảng cách Euclide, chúng ta có được những người hàng xóm gần nhất, là 3 người hàng xóm gần nhất trong loại A và 2 người hàng xóm gần nhất trong loại B. Hãy xem hình ảnh ở trên.
Chọn giá trị của K trong thuật toán K-NN?
Dưới đây là một số điểm cần nhớ khi chọn giá trị của K trong thuật toán K-NN:
- Không có cách cụ thể nào để xác định giá trị tốt nhất cho “K”, vì vậy chúng tôi cần thử một số giá trị để tìm ra giá trị tốt nhất trong số đó. Giá trị ưu tiên nhất cho K là 5.
- Giá trị rất thấp của K chẳng hạn như K = 1 hoặc K = 2, có thể bị nhiễu và dẫn đến ảnh hưởng của các giá trị ngoại lệ trong mô hình.
- Giá trị lớn đối với K là tốt, nhưng nó có thể gặp một số khó khăn về phần cứng.
Giá trị k trong thuật toán k-NN xác định có bao nhiêu lân cận sẽ được kiểm tra để xác định phân loại của một điểm truy vấn cụ thể. Ví dụ, nếu k = 1, cá thể sẽ được gán cho cùng một lớp với hàng xóm gần nhất của nó. Việc xác định k có thể là một hành động cân bằng vì các giá trị khác nhau có thể dẫn đến trang bị quá mức hoặc trang bị thiếu.
Giá trị thấp hơn của k có thể có phương sai cao, nhưng độ chệch thấp và giá trị lớn hơn của k có thể dẫn đến độ chệch cao và phương sai thấp hơn. Việc lựa chọn k sẽ phụ thuộc phần lớn vào dữ liệu đầu vào vì dữ liệu có nhiều giá trị ngoại lai hoặc nhiễu hơn sẽ hoạt động tốt hơn với các giá trị k cao hơn. Nhìn chung, bạn nên có một số lẻ cho k để tránh ràng buộc trong phân loại và các chiến thuật xác nhận chéo có thể giúp bạn chọn k tối ưu cho tập dữ liệu của mình.
Mở rộng công thức tính khoảng cách
Tóm lại, mục tiêu của thuật toán k-láng giềng gần nhất là xác định các láng giềng gần nhất của một điểm truy vấn nhất định, để chúng ta có thể gán nhãn lớp cho điểm đó. Để làm được điều này, KNN có một số yêu cầu sau:
Xác định số liệu khoảng cách của bạn
Để xác định điểm dữ liệu nào gần nhất với điểm truy vấn nhất định, khoảng cách giữa điểm truy vấn và các điểm dữ liệu khác sẽ cần được tính toán. Các chỉ số khoảng cách này giúp hình thành ranh giới quyết định, phân chia các điểm truy vấn thành các vùng khác nhau. Bạn thường sẽ thấy các ranh giới quyết định được hiển thị bằng sơ đồ Voronoi.
Mặc dù có một số thước đo khoảng cách mà bạn có thể chọn, nhưng bài viết này sẽ chỉ đề cập mở rộng những phương pháp đo khoản cách khác:
Khoảng cách Euclide (p = 2):
Đây là thước đo khoảng cách được sử dụng phổ biến nhất và nó được giới hạn ở các vectơ có giá trị thực. Sử dụng công thức dưới đây, nó đo đường thẳng giữa điểm truy vấn và điểm khác đang được đo.
Khoảng cách Manhattan (p = 1) :
Đây cũng là một số liệu khoảng cách phổ biến khác, đo giá trị tuyệt đối giữa hai điểm. Nó cũng được gọi là khoảng cách taxi hoặc khoảng cách khối thành phố vì nó thường được hình dung bằng lưới, minh họa cách người ta có thể điều hướng từ địa chỉ này đến địa chỉ khác qua các đường phố trong thành phố.
Khoảng cách Minkowski :
Thước đo khoảng cách này là dạng tổng quát của các thước đo khoảng cách Euclidean và Manhattan. Tham số p trong công thức bên dưới cho phép tạo các chỉ số khoảng cách khác. Khoảng cách Euclide được biểu diễn bằng công thức này khi p bằng hai, và khoảng cách Manhattan được biểu thị với p bằng một.
Khoảng cách Hamming:
Kỹ thuật này thường được sử dụng với các vectơ Boolean hoặc chuỗi, xác định các điểm mà các vectơ không khớp. Do đó, nó cũng được gọi là chỉ số chồng chéo.
Ứng dụng thuật toán KNN
Phân loại là một vấn đề quan trọng trong khoa học dữ liệu và học máy. KNN là một trong những thuật toán lâu đời nhất nhưng chính xác được sử dụng để phân loại mẫu và mô hình hồi quy.
Dưới đây là một số lĩnh vực mà thuật toán k-hàng xóm gần nhất có thể được sử dụng:
- Xếp hạng tín dụng: Thuật toán KNN giúp xác định xếp hạng tín dụng của một cá nhân bằng cách so sánh họ với những người có đặc điểm tương tự.
- Phê duyệt khoản vay: Tương tự như xếp hạng tín dụng, thuật toán k-gần nhất có lợi trong việc xác định các cá nhân có nhiều khả năng bị vỡ nợ hơn đối với các khoản vay bằng cách so sánh các đặc điểm của họ với những cá nhân tương tự.
- Tiền xử lý dữ liệu: Tập dữ liệu có thể có nhiều giá trị bị thiếu. Thuật toán KNN được sử dụng cho một quá trình được gọi là truyền dữ liệu bị thiếu để ước tính các giá trị bị thiếu.
- Nhận dạng mẫu: Khả năng của thuật toán KNN để xác định các mẫu tạo ra một loạt các ứng dụng. Ví dụ, nó giúp phát hiện các mô hình sử dụng thẻ tín dụng và phát hiện các mô hình bất thường. Phát hiện mẫu cũng hữu ích trong việc xác định các mẫu trong hành vi mua hàng của khách hàng.
- Dự đoán giá cổ phiếu: Vì thuật toán KNN có khả năng dự đoán giá trị của các thực thể không xác định, nên nó hữu ích trong việc dự đoán giá trị tương lai của cổ phiếu dựa trên dữ liệu lịch sử.
- Hệ thống khuyến nghị: Vì KNN có thể giúp tìm kiếm những người dùng có đặc điểm tương tự, nó có thể được sử dụng trong hệ thống khuyến nghị. Ví dụ: nó có thể được sử dụng trong nền tảng phát video trực tuyến để đề xuất nội dung mà người dùng có nhiều khả năng xem hơn bằng cách phân tích những gì người dùng tương tự xem.
- Thị giác máy tính: Thuật toán KNN được sử dụng để phân loại hình ảnh. Vì nó có khả năng nhóm các điểm dữ liệu tương tự nhau, chẳng hạn như nhóm các con mèo lại với nhau và các con chó trong một lớp khác nhau, nó rất hữu ích trong một số ứng dụng thị giác máy tính .
Đánh giá thuật toán láng giềng gần nhất
Một trong những lợi thế quan trọng nhất của việc sử dụng thuật toán KNN là không cần phải xây dựng mô hình hoặc điều chỉnh một số tham số. Vì đó là một thuật toán lười học và không phải là một người ham học hỏi, nên không cần đào tạo mô hình; thay vào đó, tất cả các điểm dữ liệu được sử dụng tại thời điểm dự đoán.
Tất nhiên, điều đó tốn kém về mặt tính toán và tốn thời gian. Nhưng nếu bạn có các tài nguyên tính toán cần thiết, bạn có thể sử dụng KNN để giải các bài toán hồi quy và phân loại. Mặc dù vậy, có một số thuật toán nhanh hơn có thể tạo ra các dự đoán chính xác.
Ưu điểm
Dưới đây là một số ưu điểm của việc sử dụng thuật toán k-hàng xóm gần nhất:
- Thật dễ hiểu và đơn giản để thực hiện
- Nó có thể được sử dụng cho cả vấn đề phân loại và hồi quy
- Nó lý tưởng cho dữ liệu phi tuyến tính vì không có giả định về dữ liệu cơ bản
- Nó có thể xử lý các trường hợp nhiều lớp một cách tự nhiên
- Nó có thể hoạt động tốt với đủ dữ liệu đại diện
Tất nhiên, KNN không phải là một thuật toán học máy hoàn hảo. Vì công cụ dự đoán KNN tính toán mọi thứ từ đầu nên nó có thể không lý tưởng cho các tập dữ liệu lớn.
Nhược điểm
Dưới đây là một số nhược điểm của việc sử dụng thuật toán k-hàng xóm gần nhất:
- Chi phí tính toán liên quan cao vì nó lưu trữ tất cả dữ liệu đào tạo
- Yêu cầu bộ nhớ lưu trữ cao
- Cần xác định giá trị của K
- Dự đoán chậm nếu giá trị của N cao
- Nhạy cảm với các tính năng không liên quan






Pingback: Decision Tree - Thuật Toán Cây Quyết định Là Gì ? - Chạy định Lượng
Pingback: KNN – Thuật toán láng giềng gần nhất K-Nearest Neighbor là gì - Phân tích kinh doanh chuyên nghiệp